Insufficient virtual memory
Program Exception - access violation
SIGSEGV, segmentation fault occurred
Out of memory
Cannot ALLOCATE
这些情况下,就有可能(但不一定)是内存不足。尤其在程序中具有较大量的数组时,碰到的几率就更大了。
一.内存能用多少?
这不是一个简单的概念。就语法规则来说,Fortran并没有规定数组大小的上限。
而不同编译器则自己有自己的限定。比如一些编译器限制为:9,223,372,036,854,775,807
这个数字是 2**63-1,在绝大多数的情况下,这是完全够用的。
然而,我们的实际使用内存限制,往往是来自操作系统和软硬件环境的。
例如,32位的操作系统,通常只有 2**32 的内存可用范围。大约就是 2GB。虽然物理内存可能有更多,比如 8GB,但每一个应用程序的进程,都只有 2GB 的内存可供寻址。一些情况下,应用程序源代码所能使用的内存空间,其实只有 1.5GB 左右。
而 64位的操作系统看起来寻址空间足够大,但往往也受操作系统的影响,每个进程能用到16GB左右就算不错了。
二. 怎么计算数组占用了多少内存?
首先,我们应该了解普遍的数据类型,分别占用多少内存?
例如 integer , real 普遍的编译器规定占用 4 字节。而双精度占用 8 字节。
complex 复数占 8 字节,双精度 complex 占 16 字节。
那么我们假设一个 real(8) 的双精度数组:myArray( 1000 , 500 , 200 )
则它总共有的数据个数 = 1000 * 500 * 200 = 100000000 个
由于是双精度,每个占 8 字节,一共 800000000 字节,除以 1024 为 KB 数,再除以 1024 为 MB 数
即:762.9394 MB
这个数组还是蛮大的。假如只有一个这样的数组,32位系统可能还能跑起来。而如果有两个,32位系统则可能跑不起来,而出现本文一开始提到的那些错误。
三. 32位和64位的一些问题
这里我们需要分清楚几个位数的区别:
CPU 位数,操作系统位数,编译器位数,编译后的程序的位数。他们都是不同的概念,但彼此之间有相互的关系。
1. 使用64位的CPU跑64位操作系统,也可以跑32位的操作系统。但32位的CPU,通常只能跑32位操作系统。
2. 使用32位编译器,可编译得到32位可执行程序。使用64位编译器,可得到64位可执行程序。
3. 得到32位的可执行文件,可以在32位操作系统或64位操作系统上运行。而得到64位的可执行文件,只能在64位操作系统上运行。
4. 编译器有32位和64位的差别,但往往他们一起提供下载。在使用时,通过选项来控制使用哪一个。
5. 对于64位编译器本身,它是32位的,但它编译后的可执行文件是64位的。
6. 静态链接库(lib)和动态链接库(dll)也有32位和64位的区别。它一般与主程序的位数一致。也就是说,像IMSL、MKL 这些函数库是由32位和64位的差异的。
四. 内存还是不够,怎么办?
硬件的发展,永远跟不上科学计算的需求。这是永恒的真理。
当我们遇到内存不足时,经常有人会调大windows的“虚拟内存”来试图解决,但往往没有成效。这可能是把 virtual memory 当做了“虚拟内存”,而实际上,这里的 virtual memory 是相对于真实的物理内存而言的,表示windows将真实物理内存映射为平坦模式的虚拟内存 virtual memory(这涉及到操作系统的内存管理模式,详见其他资料);而我们一般说的“虚拟内存”,是指硬盘上的“页面文件(pagefile)”,实际上,两者并不是一回事,只是翻译比较接近。
面对内存不足,通常从几个方面寻求答案:
1. 你是否真的需要那么大的内存?
这是绝大多数情况,应该首先考虑的问题。
例如说,有的文件有很多很多行,我们需要分别处理并输出。但前面的行并不影响后面的行,那么我们就不需要定义一个大的数组,而只定义一个变量,每次循环都重复利用它。
2. 是否可以考虑换用64位,或更高性能的计算平台。
有的时候,我们认为操作系统是64位的,但其实编译器没有选择为64位的编译器,而导致实际还是32位的可执行文件。内存有1.5GB左右的限制。
PS:内存不足经常与堆栈不足相互混淆。很多人都不容易区分这两者。由于编译器本身的缺陷,很多时候也不能很好的提示到底是内存不足,还是堆栈不足。
在一部分的情况下,内存(稍微)不足,还可以尝试开启编译器的大内存地址支持。例如IVF可以这样设置:
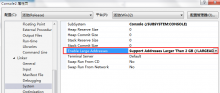
大图
3. 是否可以改进算法,把一些不必要的内容先存储在硬盘上,而不是全部放在内存里。
我们有一门专门的学问,叫大型稀疏矩阵。是用特殊的数据结构来存储大型但稀疏(绝大多数元素为0)的矩阵的。如果你的情况是这种,不妨研究一下。
此外,我们知道,腾讯QQ有数十亿的用户,但QQ的服务器上,并没有一个几十亿的数组。而是存储在数据库里,根据需要去调取。
我们也知道,我们要播放40集的电视剧,播放器只是打开一个列表,而内存里只有一段时间的视频信息。其他暂时不播放的信息,存放在硬盘上。当播放到某个段落时,再读入内存播放。
这就是我们编程时,经常用到的方法,即,把较大的数据存入硬盘,而保留当前需要处理的部分在内存里,当计算到其他部分时,再从硬盘读入计算。
是的,笔者知道,从硬盘读入内存,是需要花费时间的。但是,往往时间和空间不可兼得,这就像生活一样!