很多朋友学习过 Matlab,Javscript,VBScript 一类的程序设计。它们的变量可以不需要定义,或者定义时无需特别指定它的类型。
稍微专业的说法,这种语言特性被称为 “弱数据类型”。而 Fortran,C/C++ 等,属于 “强数据类型”。
弱数据类型,在定义时可以不必指定数据类型,精度。在使用时再确定,它的优点是灵活,多变。缺点是容易出错,效率低。往往是脚本语言具有。
强数据类型,强制要求指定数据类型,且必须经过特别的转换,否则无法通用。显然,它的优点就是安全,执行效率高。往往是编译型语言具有。
做为一个以严谨的科学计算见长的编程语言,Fortran 是强数据类型的。使用变量前,必须说明他的精度和大小。这就是变量或数组的定义!
PS:定义和声明在概念上并不相同。有兴趣的朋友可查阅其他资料了解,但作为大多数Fortran程序员来说,不必区分两者。本文中也不区分。
同时,需要注意的是,Fortran 与 C/C++ 同具有“强数据类型”定义。但 C/C++ 允许定义语句出现在执行语句中间,而 Fortran 不允许。一个程序单元,必须先写完全部定义语句,然后才能写执行语句。
第二,关于 Implicit 和 IN 规则
Fortran 虽然是强数据类型的,但由于 Fortran 出现得很早,而早期的计算机资源非常稀缺。早期打孔卡片输入程序,如果源代码简短则可以节约很多成本。因此,早期 Fortran 遗留了一个很不好的特性,这就是 IN 规则。
IN 规则规定,假如源代码中没有对变量(或数组)进行定义,则以 I J K L M N 开头的变量为整型变量(或数组),其他变量为实型变量(或数组)。
看起来,IN 规则很酷,它可以减少大量的源代码,可以将很多定义语句省略。在早期,它也确实节约了很多成本。
然而,现在的计算机资源已经非常廉价了,我们没必要为了几KB的硬盘空间来省略定义语句。因此,我们建议,避免在程序中使用 IN 规则。
方法是:在每一个程序单元,添加 Implicit None 语句。并显式定义全部的变量和数组。
每一个程序单元,意思是:主程序,全部子例行程序和函数,全部 Module 模块。
(实际上,如果module中添加了这个语句,它 contains 下的函数无需再次添加它)
使用 Implicit None 有很多好处,例如以下代码,输入半径求圆的面积:
Program www_fcode_cn Implicit None !//如没有此行,结果会无法预料 Real , parameter :: PI = 3.1415926 real :: r Read( * , * ) r Write( * , * ) '圆面积为:' , P1 * r * r End Program www_fcode_cn
我们定义了 PI 为圆周率,但是第6行,我们误把PI写成了P1(字母I 写为了数字1)。
在没有 Implicit None 的情况下,编译器会认为 P1 是另一个变量,IN 规则规定,P开头的变量为实型。于是,P1的值由于未初始化而不确定,程序不会出错,但结果可能不是我们想要的。
如果我们书写了第二行的 Implicit None,取消了 IN 规则。那么编译器遇到 P1,发现未定义,就会给出错误提示。
在一部分编译器上,错误提示可能为:error #6404: This name does not have a type, and must have an explicit type. [P1]
除此之外,Implicit None 还可以避免因数据类型,精度不同而引起的计算结果不正确。 因此,我们强烈建议您书写代码时,每一个程序单元一开始添加 Implicit None 语句!
当然,如果你正在修改长度较长的老代码,再去添加它会增加你的工作量。此时就需要慎重考虑了。
另外,Implicit 有其他的用法,例如:Implicit Real*8(A-H,O-Z) ,它表示 A-H 开头和 O-Z 开头的变量,为双精度实型。这种用法同样存在上述问题,因此也不建议使用,只要看到它知晓它的含义既可。
我们建议 Implicit 后面一定紧跟 None。
第三,定义变量和数组的风格
同样由于历史原因,有很多陈旧的定义变量和数组的语句。在新的语法下,我们不建议再使用它们。
1. PARAMETER
在旧的教材里,会建议程序员使用 PARAMETER 来定义常数。新的语法下,我们建议将 PARAMETER 作为修饰符。
例如:
PARAMETER(N=6,M=7)
Integer , parameter :: N = 6 , M = 7
前一句是旧语法,只规定了N和M是常数,数值分别是6和7。
后一句是建议使用的新语法,除了上述信息之外,还规定 N 和 M 都是 Integer 整型
2. DIMENSION
在旧的教材里,会建议程序员使用 DIMENSION 来定义数组。新的语法下,我们建议将 DIMENSION 也作为修饰符,甚至直接忽略它。
例如:
REAL A , B
DIMENSION A(3,3) , B(4,4)
Real :: a( 3 , 3 ) , b( 4 , 4 )
前两句是旧语法,先规定了A和B是实型,然后规定它们是多大的数组。
最后一句是建议使用的新语法,把两句合并为一句,不但书写方便,还更便于阅读。
注意,不要单独使用 DIMENSION 语句,因为它只指定数组的大小,而不规定其类型和精度,如果只有 DIMENSION 语句,则依然沿用 IN 规则。
3. 关于双冒号
在新的语法里,很多变量类型后书写两个冒号,然后是变量名。
双冒号,表示修饰符的结束。例如:
Integer , parameter , private :: fcode( 3 , 3 )
Integer 是变量类型,它有两个修饰符:parameter 和 private,两个冒号表示修饰符结束了,也就是说,如果有修饰符,则必须有双冒号。
语法还规定,如果定义变量时,同时对其赋予初始值,则变量默认具有 save 属性,此时相当于隐藏了 save 这个修饰符,因此也必须有双冒号。
例如:integer :: a = 0 ,他实际是 integer , save :: a = 0 ,因此不能简写为:integer a=0
因此,我们也建议在所有定义语句中使用双冒号。
第四,关于 Kind 值
Kind 值是用于说明变量所占内存空间的。对于整型变量,它只影响整型表达的最大最小值。对于实型变量和复数变量,还影响它的精度。
绝大多数32位编译器,默认 Kind 值的整型变量和实现变量占有 32 位,即 4 字节。而复数变量占有 8 字节(实部虚部各占有 4 字节)。
我们可以设定不同的 Kind 值来修改变量所占的字节数。需要注意的是,不同的编译器产品,对 Kind 值的支持也不同。通常来说,64位编译器允许更高值的 Kind 值。
您可以查看本站对各编译器的对比文章,来了解不同编译器对 Kind 值的支持(语法支持中第10项 - 第12项目):/codetools-28-1.html
在绝大多数编译器来说,Kind = 4 表示 32 位变量,Kind = 8 表示 64 位变量。
大家习惯称呼 Kind = 4 的整型为 整型,而 Kind = 8 的整型为长整型。Kind = 4 的实数叫单精度,而 Kind = 8 的实数叫双精度。
对于其他 Kind 值的整型和实型,没有统一的称呼。不同编译器的支持也不同。
同时,如果不书写 Kind 值,不同的编译器也有默认的 Kind,大多数32位编译器默认的 Kind 值是 4。某些编译器还可以通过设置来改变默认 Kind 值。例如 IVF 编译器,可通过下图设置:
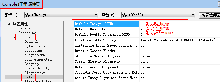
大图
对于双精度来说,早期 Fortran 提供了 Double precision 关键字来定义它。就新语法来说,我们不再建议使用这个关键字。而统一使用 Kind 值进行定义。例如:
!// 写法一 Real(4) :: rV1 Real(8) :: rV2 Double precision :: rrV3 , rrV4
建议写为:
!// 写法二 Real( Kind = 4 ) :: rV1 , rV2 !// 单精度变量 Real( Kind = 8 ) :: rrV3 , rrV4 !// 双精度变量
这样做的好处就是,我们可以把变量的精度作为常量定义起来,方便以后修改。例如:
!// 写法三 Integer , parameter :: myKIND = 4 Read( Kind = myKIND ) :: rr1 , rr2 , rr3 Read( Kind = myKIND ) :: rr4 , rr5 , rr6 !......
假如省略号后面还有100条单精度实型的定义语句,将来我们希望把他改为双精度,则只需要第一句,把 myKIND = 4 修改为 myKIND = 8 既可,而不必修改100多条语句。这在大型程序里非常有用。
最后,还需要说明的是,Kind = 4 或 8 代表什么含义,不同编译器也不同。所以,上面的代码可能在 IVF 或 CVF 下可以正常运行,但到了其他编译器,例如 Silverfrost Ftn95 下,就不行了。原因是 Ftn95 对 Kind 值的规定与IVF不同。
为了解决这一问题,可以使用 SELECTED_REAL_KIND 和 SELECTED_INT_KIND 这两个预编译函数。之所以说是“预编译函数”,而不说是“函数”,是因为这两个东西并不执行,不是执行语句,而是编译前直接确定,它属于定义语句,可以放在定义语句里(当然也可以放在执行语句里)。
SELECTED_INT_KIND( r ) 用于返回一个 KIND 值,使得这种 KIND 值的变量能够表达 -10^r 到 10^r 之间的所有数。
比如:Integer , parameter :: myINT = SELECTED_INT_KIND( 8 )
它在 IVF 系列编译器上,myINT 会赋予 4 的值,含义是,IVF 上,KIND=4 的整型,就足够表达 -10^8 到 10^8 之间的数了。
它在 Ftn95 编译器上,myINT 会赋予 3 的值,含义是,Ftn95 上,KIND=3 的整型,就足够表达 -10^8 到 10^8 之间的数了。
SELECTED_REAL_KIND( p , r ) 用于返回一个 KIND 值,使得这种 KIND 值的变量能够表达-10^r 到 10^r 之间的所有数,且精度可精确到 p 位有效数字。
比如:Integer , parameter :: myREAL = SELECTED_REAL_KIND( 6 , 70 )
它在 IVF 系列编译器上,myREAL 会赋予 8 的值,含义是,IVF上,KIND = 8 的实型,才能够表达 -10^70 到 10^70 之间的数,且精度在 6 位有效数字以上。
它在 Ftn95 编译器上,myREAL 会赋予 2 的值,含义是,Ftn95上,KIND = 2 的实型,才能够表达 -10^70 到 10^70 之间的数,且精度在 6 位有效数字以上。
需要注意的是,虽然 IVF 和 Ftn95 返回的 KIND 值不同,但实际占有的内存数,是一样的。只不过这两种编译器用不同的 KIND 值代表他们而已。
因此,使用 SELECTED_INT_KIND 和 SELECTED_REAL_KIND 可以让代码更具有通用性,使得代码可以在不同平台的不同编译器上通用。
综合来说,最佳的定义方式是这样:
!// 写法四 Implicit None Integer , parameter :: myINT = SELECTED_INT_KIND( 8 ) Integer , parameter :: myREAL = SELECTED_REAL_KIND( 6 , 70 ) Integer( Kind = myINT ) :: iVar1 , iVar2 Real( Kind = myREAL ) :: rrVar1 , rrVar2 Real( Kind = myREAL ) :: rrVar3 , rrVar4
从写法一到写法四,虽然书写起来越来越麻烦,但是适用性,可修改性越来越强,因此,写法四是值得的,也是我们推荐的。