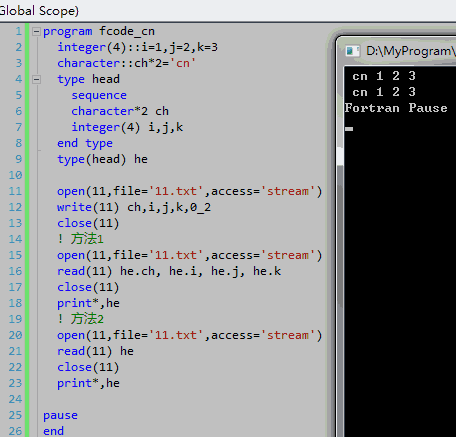
在讲这个问题之前,我们先看一段代码:
program fcode_cn
integer(4)::i=1,j=2,k=3
character::ch*2='cn'
type head
!sequence
character*2 ch
integer(4) i,j,k
end type
type(head) he
open(11,file='11.txt',access='stream')
write(11) ch,i,j,k
close(11)
! 方法1
open(11,file='11.txt',access='stream')
read(11) he.ch, he.i, he.j, he.k
close(11)
print*,he
! 方法2
open(11,file='11.txt',access='stream')
read(11) he
close(11)
print*,he
pause
end
代码开头先向文件11.txt中写入一个字符串”cn” 和3个4字节整数1, 2, 3 ,然后分别使用方法1和方法2读取并输出数据。从代码本身分析,我们向文件中写入了14个字节的信息,方法1和方法2均用结构体去读取这个14字节信息。理论上说,这不存在问题,但是在执行时,我们遇到下面的错误(图1):
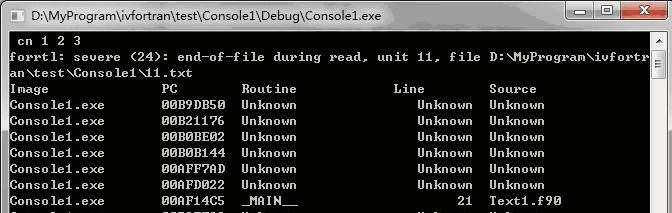
读取同样的数据为什么方法1能够正确执行,而方法2却遇到文件尾呢?这跟结构体元素的对齐方式有关。
打开项目属性-Fortran-data,点开structure member alignment选项(如图2),查看对齐方式,有1字节、2字节、4字节、8字节和16字节,win32系统缺省为4字节。
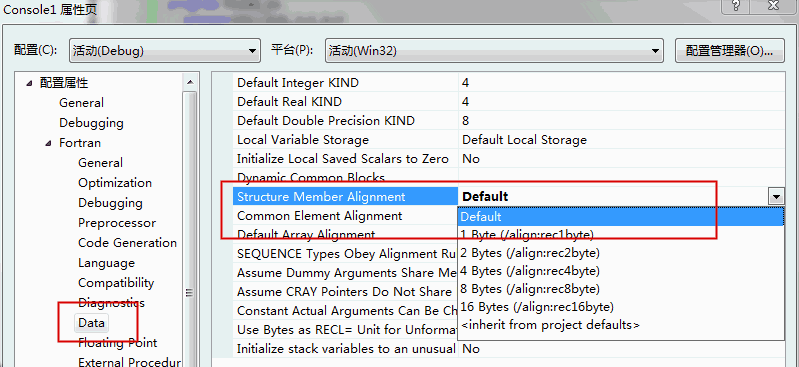
现在我们来解释上面出现的错误。由于win32系统缺省对齐方式为4字节,在使用方法2进行文件读取的时候,每次从文件中读取4字节数据,依次赋值给变量ch, i, j, k。因此需要读取4×4=16字节信息,但文件中仅有14字节信息,故出现如上错误。
为避免以上错误:
一是采用方法1进行读取,但如果结构体太复杂,比如为SEGY数据道头时,这种方法不可取;
二是将structure member alignment选项设置为1字节,这依赖于编译器设置,可移植性较差。
我们推荐另一种解决方案,即在结构体定义部分加上sequence指令:
type head
sequence
character*2 ch
integer(4) i,j,k
end type
如此,我们就可放心使用方法2进行数据读取(图3)。有关sequence的详细介绍可参考帮助文档。