fortran 90
szw_sh@163.com
2018-05-12
相关资料来源于网络。按照常用字、常用读音优先原则选取读音首字母,首字母以小写字母表示。
汉字GBK码为双字节,范围为8140-FEFE,首字节129-254,尾字节64-254。定义了一个一维数组保存汉字首字母,下标值 +1,使得下标可以从1开始。下标=(首字节-129)*191+(尾字节-64)+1。
汉字GBK码大约有25%编码为各种非汉字符号,其拼音首字母设为空格字符。GBK码有21003个汉字,收集到20887个拼音,剩余116个生僻字没找到拼音。
! 汉字拼音首字母索引数组引用示例
! szw_sh@163.com
! 2018-05-12
! fortran 90
Program fcode_cn
use md_idx
Implicit None
character(len=*) , parameter :: h='汉字拼音首字母索引数组示例'! 定义示例汉字字符串
character(len=len(h)/2) :: py ! 用于保存对应首字母的变量
character(len=len(h)) :: h1
character(len=len(py)) :: py1
integer :: i , j = 0 , k , n
Do i=1,len_trim(h),2 ! 顺序对汉字处理
k=md_Char2Index(h(i:i+1)) ! 计算汉字GBK码对应idx数组的下标
j=j+1
py(j:j)=md_index(k:k) ! 将拼音首字母按顺序写入字符串
End Do
write(*,'(1x,a)') h
!write(*,'(1x,a)') py
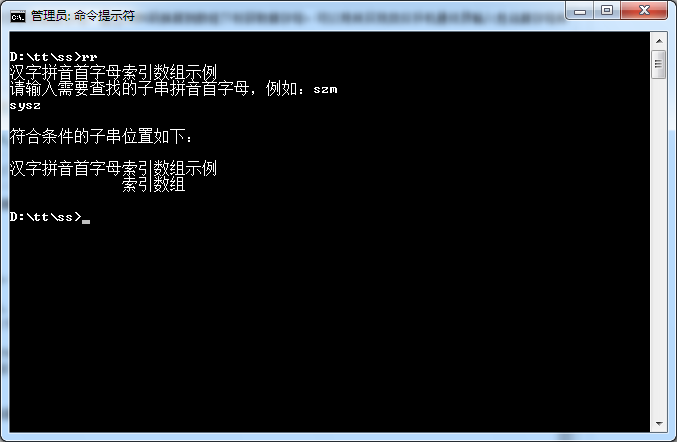
write(*,'(1x,a)') '请输入需要查找的子串拼音首字母,例如:szm'
read(*,'(a)') py1
k=len_trim(py1)
n=index(py,py1(1:k))
if( n < 1 ) stop '示例字符串中不包含查询子串'
h1=h
h1(1:2*(n-1))=' '
h1(2*(n+k)-1:)=' '
write(*,'(/1x,a,/)') '符合条件的子串位置如下:'
write(*,'(1x,a)') h
write(*,'(1x,a)') h1
End Program fcode_cn
调用方法为:
use md_idx,通过换算GBK码对应的数组下标获取拼音首字母。 /uploadfile/2018/0516/20180516025346513.f90
use md_idx,通过换算GBK码对应的数组下标获取拼音首字母。 /uploadfile/2018/0516/20180516025346513.f90
演示如何使用该模块进行汉字快速查询